La commande describe ne fonctionne pas sous Sybase en revanche la commande sp_help nom_de_table (nom_de_view) fonctionne.
L'autre solution est d'utiliser le client de Sybase qui fournit ces informations pratiquement directement.
vendredi 26 octobre 2007
mardi 23 octobre 2007
Mesure des performance d'une application WEB
Pour un sujet si complexe, il est pratiquement impossible, d'adresser toutes les problématiques dans un seul exposé. Je m'efforcerais de rester aux exigences les plus courantes que tente de vérifier une étude de performance. Nous nous attachons au cas d'une application WEB à visibilité grand public.
Objectifs
Dans la plupart des cas, une étude de performance vise à ce qu'une application réponde rapidement à un utilisateur. Or cette rapidité est un critère psychologique . Un être humain fonde sa détermination de la rapidité : A partir de la complexité qu'il suppose, du prix qu'il accorde à son action, de son âge. C'est à dire qu'une transaction bancaire peut psychologiquement tarder plus que le visionnage d'une publicité.
Toute hypothèse sur l'utilisateur est donc vaseuse, deux utilisateurs ne font pas la même utilisation de performance, c'est pourtant par là qu'il faut commencer. Un utilisateur n'a généralement pas une utilisation prudente d'un logiciel, il vaut mieux donc supposer qu'il clique n'importe comment. Sur une connexion haut-débit, on considère qu'un utilisateur n'attend pas si le temps de réponse est inférieur à deux secondes et l'application doit fonctionner de manière continue.
A partir de là on détermine en gros les critères objectifs :
Rapidité
2 secondes en moyenne pour que service réponde quelques soit l'action
Charge
2000 visiteurs simultanés
Stabilité
Le système doit être stable
Tester les performances
Bien qu'une étude de performance appelle des réponses essentielement techniques, la mesure des performances d'une application ne constitue pas une fin en soi. En effet, la vitesse de traitement et l'occupation mémoire d'une application (la qualité de la programmation) ne suffit pas à mesurer la qualité dans d'une application. L'étude de la performance d'une application doit donc être menée en veillant à ne pas s'éloigner du réel. Tous les aspects techniques sont considérés en gardant à l'esprit ce fil rouge.
Les critères usuels sont :
Stabilité
Rapidité
Capacité de tenir la charge
Rapidité
La rapidité renseigne sur la vtesse d'un traitement. C'est un critère mesurable qui doit être mis en rapport avec la capacité de charge ( elle influencera grandement ce paramètre)
Chaque temps de réponse sera mis en relation avec une charge. L'utilisateur final est l'étalon pour la rapidité.
Charge
C'est la capacité à traiter simultanément un grand nombre de requêtes. On distingue deux seuils :Le seuil au delà duquel le temps de réponse devient inacceptable
Le seuil d'écroulement
Stabilité
C'est la capacité pour l'application de fonctionner longtemps sans être redémarrée. Le java, avec son garbage collector fournit de fortes garanties de stabilité. Cependant, si l'on se sert de concept un peu avancés comme les Threads, ce genre de problème peut survenir.
On peut qualifier l'instabilité
Par la charge qui provoque l'écroulement
Par le nombre de jours sans redémarrage
Moyens et condition de fonctionnement réel
Un test est d'autant plus pertinent qu'il reproduit les moyens et les conditions réelles de la production.
Serveur production :
Mémoire vive : 2 Go
Vitesse processeurs : 1,5 GHz
Nombre serveurs : 2
Nombre d'applications : 4
Niveau de log INFO
Equilibrage de charge : OUI
On suppose que le débit réseau n'est pas problématique
Moyens et condition de fonctionnement de test de charge
Pour les tests de charge, nous ne disposons pas des outils permettant de reconstituer une expérience utilisateur, nous avons quelques restrictions et nous livrant à certaines approximations :
Nos moyens nous permettent seulement de faire le test dans un contexte n'incluant pas les étapes d'identification. C'est une hypothèse optimiste que de croire que l'identification ne sera pas pénalisante, d'un autre coté, elle ne dépend pas de l'équipe AIDA.
Nous nous baserons sur la requête la plus pénalisante pour le système, nous plaçant dans un cas passimiste. La requête la plus pénalisante est celle qui insterroge tous les partenaires.
La requête sera toujours identique, sur du HTTP, portera toujours sur le même utilisateur et le même dossier.
Objectifs techniques
Estimation
Nombre d'utilisateur potentiel
C'est le nombre total d'utilisateurs capable de se connecter sur le site.
Nombre de visiteurs simultanés
C'est le nombre estimé de visiteurs simultanés sur le site en période chargée
Nombre d'actions moyenne d'un utilisateur
C'est le nombre de requête qu'un utilisateur est succeptible de déclencher pendant sa visite sur le site.
Site à pic de charge
Un site à pic de charge est périodiquement plus chargé (En dehors des cycle naturel jour/nuit et hebdomadaires)
Equlibrage de charge
L'équilibrage de charge intervient au niveau de l'exploitation, aussi il nous avons déjà la garantie d'avoir un système scalable.
Le temps moyen d'une session
C'est le temps moyen d'une session estimé. Mieux veut prévoir court.
Facteur de zapping
Plus il est facile de se déplacer dans l'application et de déclencher des actions, plus les actions seront effectivement déclenchées. Donc un site à clics provoquent un surcroit de requêtes.
Nombre d'utilisateur potentiel : 200000
Nombre de visiteurs simultanés : 2000
Nombre d'actions moyenne d'un utilisateur : 4
Site à pic de charge : Déclenchement ou pas de pic de charge : oui
Le temps moyen d'une session : 5 mn
Facteur de zapping : x 2
A l'aide de ces informations, on pourra se faire une idée du nombre de requêtes effectuées chaque unité de temps, cela demeure cependant indicatif.
2000 x 4 x 2 /5 = 3200 requête/mn
soit 3200 /60 = 53 requête/s
Utilisation de Jmeter
Jmeter permet de lancer des requêtes http en spécifiant des contraintes temporelle (Echelon et cycles)
Scénarios
On définit plusieurs scénarios de charge :
Charge instantanée
On envoie 50 requêtes liste dossier en 1 seconde, chaque requête ne répond que lorsque l'ensemble des dossiers est rappatrié.
La requête envoyée au serveur WS est toujours la même. La réponse l'est également.
Charge durant une minute
On envoie 3000 requêtes en 60 secondes (non effectué)
Résultats
Pour chaque résultat on présente :
Le temps moyen qui est le temps que met en moyenne une requête pour répondre. Il fait la sytnhèse des bonnes et des mauvaise expériences utilisateurs. Plus les résultats ont une forte dispertion et plus il faut traiter cette donnée avec circonspection.
Le temps médian qui est le temps qu'expérimente un utilisateur moyen. Il donne la rapidité d'une requête pour un utilisateur faisant une expérience normale du produit.
La déviation (Ecart-type) donne une représentation de la dispersion des résultats. Elle donne une idée des processus(Thread) zombies.
15 itérations de charge instantanée 50 requêtes
Temps moyen : 18 sec
Temps médian : 17 sec
Temps médian : 18 sec
Serveur sur machine bureautique, partenaire réels proxié
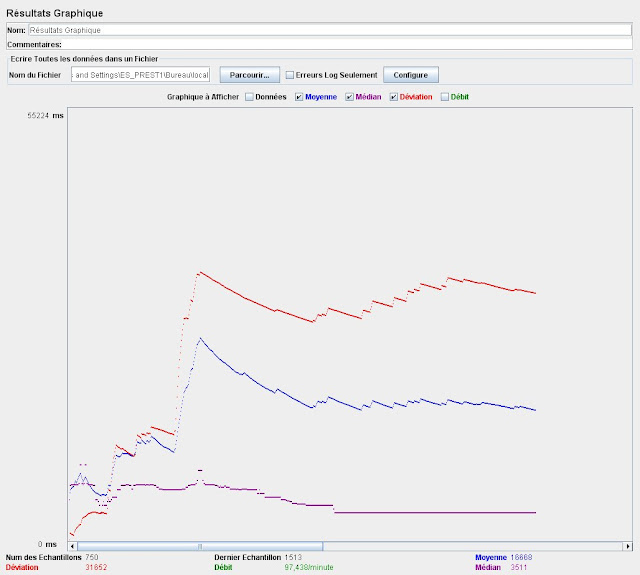
Temps moyen : 16 secTemps moyen : 16 sec
Temps médian : 3,5 sec
Deviation 18 sec
Configuration : Serveur sur machine bureautique, partenaire bouchons proxié sans latence
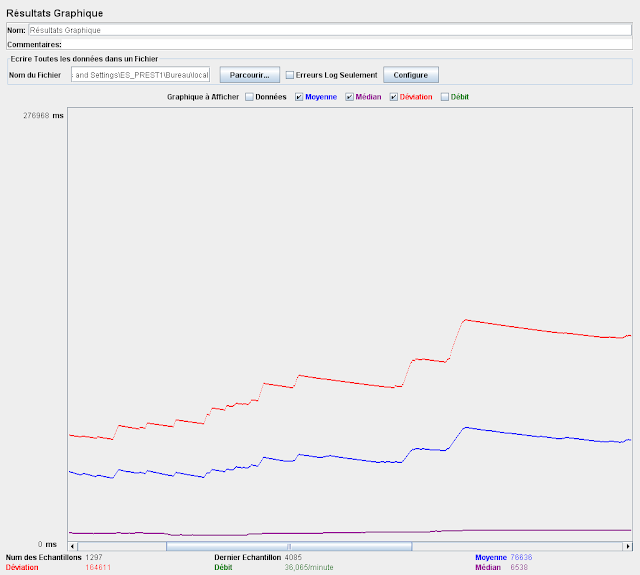
15 itérations de charge instantanée 100 requêtes
Configuration : Serveur sur machine bureautique, partenaire bouchons proxié sans latence
Temps moyen : 32 sec
Temps median : 3,5sec
Deviation : 87 sec
15 itérations de charge instantanée 150 requêtes
Configuration : Serveur sur machine bureautique, partenaire bouchons proxié sans latence
Temps moyen : 32 sec
Temps median : 3,5sec
Deviation : 87 sec
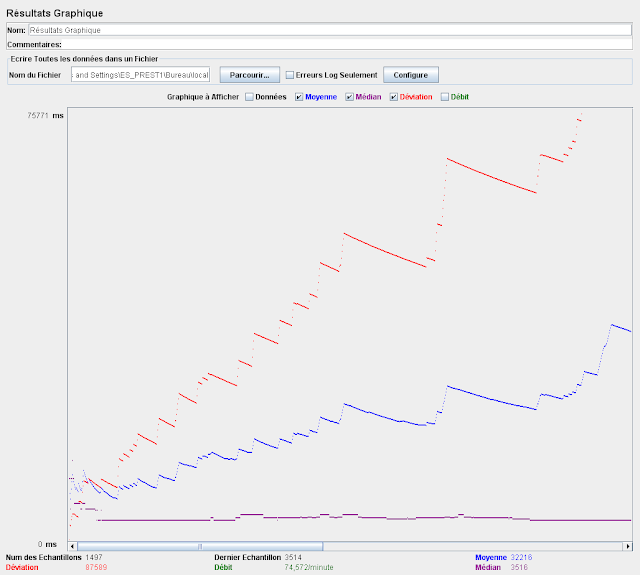
Conclusion
Dans les situations ou le serveur bouchon est utilisé, ces résultats montrent que la dispersion croit avec la charge, pour autant le temps de réponse médian reste du même ordre de grandeur.
Cette dispersion peut être expliquées par un deadlock dans la partie-core (Qui pourrait être dangereux). Elle peut être également expliquée par une saturation des partenaires, comme nous n'utilisons qu'une simulation de partenaires (Et qu'il est fort probable que les ressources des partenaires ne saturent pas aussi facilement) Il faut donc continuer les test en se servant de partenaires réel plutôt que les bouchons.
Pour ce qui concerne la stabilité : plus le serveur est fragilisé, plus il se fragilise. Il faut donc éviter les zones rouges.
Ces test mettent également en évidence qu'il est nécessaire de mesurer les performances des partenaires depuis le MAP.
mercredi 10 octobre 2007
Mounting samba file
I had some trouble performing a samba mount using Mandriva 2006
mount -tsmbfs //10.202.57.110/clunch /mnt/calam/ -ousername=tareum
dmesg displayed the following error :
mount_data version 1919251317 is not supported
I had to use the cifs type for mounting (Probably a more modern standard for the samba filesystem)
mount -tcifs //10.202.57.110/aidacalam /mnt/calam/ -ousername=tareum
You can now have a look in the /etc/mtab file copy/paste the following line in the /etc/fstab line to have the block mounted on startup/
//10.202.57.110/aidacalam /mnt/calam cifs rw,username=tridge,password=foobar 0 0
mount -tsmbfs //10.202.57.110/clunch /mnt/calam/ -ousername=tareum
dmesg displayed the following error :
mount_data version 1919251317 is not supported
I had to use the cifs type for mounting (Probably a more modern standard for the samba filesystem)
mount -tcifs //10.202.57.110/aidacalam /mnt/calam/ -ousername=tareum
You can now have a look in the /etc/mtab file copy/paste the following line in the /etc/fstab line to have the block mounted on startup/
//10.202.57.110/aidacalam /mnt/calam cifs rw,username=tridge,password=foobar 0 0
jeudi 4 octobre 2007
Bonne pratique pour gérer les environnement multiple dans maven
A chaque fois qu'un fichier représente un élément de configuration :
- fichier de propriétés
- fichier de configuration des log
- fichier de configuration hibernate
etc.
Il doit être aisément modifiable, c'est à dire qu'il ne doit pas se trouver dans un jar mais se trouvé dans un fichier facilement modifiable. Dans une application Web on placera le fichier de log4j.properties, hibernate.cfg.xml dans le répertoire classes. Ainsi, ces répertoire sont facilement modifiable par un intervenant qui ne connait a priori rien au fonctionnement de l'application.
Quand une application Web utilise un librairie, il ne faut donc pas qu'elle contienne de ressource susceptible d'interférer avec sa propre configuration. Concrètement, il faut éviter de mettre les fichier de configuration dans les partie
src/main des application et les mettre dans le repertoire test.
Il arrive parfois que la configuration soit une tache complexe et qu'il ne s'agisse pas de modifier quelques lignes mais de nombreuse modifications auquels cas il est plus approprié d'effectuer une copie pure et simple des fichiers de configuration et de garder ceux-ci dans le référentiel de sources.
Pour ce genre de problématique, maven a un mécanisme permettant de constituer un package et sa configuration à partir d'un ensemble de fichiers groupé dans un répertoire. Le mécanisme utilisé s'appelle profil. L'utilisation d'un profil conditionne le comportement de maven, il est selectionné par maven en tapant la commande -P
Supposons qu'on ai 4 environnements :
- Développement
- Test
- Recette
- Production
Pour créer un package, on spécifie le profil utilisé. Par exemple mvn -Ptest
Pour gérer ces différents environnements, on créé autant de profils dans le fichier settings.xml qui se trouve dans $HOME/.m2
Ainsi, chaque fois que l'on tape mvn -Pprod on utilise le profil de production. La configuration des plugin et un ensemble de propriétés d'éxécution sont définies à ce moment. Dans cet exemple on ne configure que les propriétés, ainsi la propriété mode est définie à dev quand on est dans l'environnement de développement.
activeProfile permet de déterminer le profil par défaut (dev)
Pour avoir des ressources différenciées, on peut se servir du filtering maven. Le filtering effectue des substitution lors des copies de ressources. Toutefois, il est plus commode lorsque les modifications sont importantes et portent sur des fichiers en entier d'avoir recours à des répertoires différentiés.
Ainsi on a la structure de répertoire suivante :
- main/resources/resources qui contient les resources communes
et
- main/resources/dev
- main/resources/test
- main/resources/recette
- main/resources/prod
qui contiennent les ressources spécifiques à des environnements.
On modifie le descripteur de projet en modifiantle pom.xml
- fichier de propriétés
- fichier de configuration des log
- fichier de configuration hibernate
etc.
Il doit être aisément modifiable, c'est à dire qu'il ne doit pas se trouver dans un jar mais se trouvé dans un fichier facilement modifiable. Dans une application Web on placera le fichier de log4j.properties, hibernate.cfg.xml dans le répertoire classes. Ainsi, ces répertoire sont facilement modifiable par un intervenant qui ne connait a priori rien au fonctionnement de l'application.
Quand une application Web utilise un librairie, il ne faut donc pas qu'elle contienne de ressource susceptible d'interférer avec sa propre configuration. Concrètement, il faut éviter de mettre les fichier de configuration dans les partie
src/main des application et les mettre dans le repertoire test.
Il arrive parfois que la configuration soit une tache complexe et qu'il ne s'agisse pas de modifier quelques lignes mais de nombreuse modifications auquels cas il est plus approprié d'effectuer une copie pure et simple des fichiers de configuration et de garder ceux-ci dans le référentiel de sources.
Pour ce genre de problématique, maven a un mécanisme permettant de constituer un package et sa configuration à partir d'un ensemble de fichiers groupé dans un répertoire. Le mécanisme utilisé s'appelle profil. L'utilisation d'un profil conditionne le comportement de maven, il est selectionné par maven en tapant la commande -P
Supposons qu'on ai 4 environnements :
- Développement
- Test
- Recette
- Production
Pour créer un package, on spécifie le profil utilisé. Par exemple mvn -Ptest
Pour gérer ces différents environnements, on créé autant de profils dans le fichier settings.xml qui se trouve dans $HOME/.m2
<settings>
[...]
<profiles>
<profile>
<id>dev</id>
<properties>
<mode>dev</mode>
</properties>
</profile>
<profile>
<id>recette</id>
<properties>
<mode>recette</mode>
</properties>
</profile>
<profile>
<id>test</id>
<properties>
<mode>test</mode>
</properties>
</profile>
<profile>
<id>prod</id>
<properties>
<mode>prod</mode>
</properties>
</profile>
</profiles>
<activeProfiles>
<activeProfile>dev</activeProfile>
</activeProfiles>
[...]
</settings>
Ainsi, chaque fois que l'on tape mvn -Pprod on utilise le profil de production. La configuration des plugin et un ensemble de propriétés d'éxécution sont définies à ce moment. Dans cet exemple on ne configure que les propriétés, ainsi la propriété mode est définie à dev quand on est dans l'environnement de développement.
activeProfile permet de déterminer le profil par défaut (dev)
Pour avoir des ressources différenciées, on peut se servir du filtering maven. Le filtering effectue des substitution lors des copies de ressources. Toutefois, il est plus commode lorsque les modifications sont importantes et portent sur des fichiers en entier d'avoir recours à des répertoires différentiés.
Ainsi on a la structure de répertoire suivante :
- main/resources/resources qui contient les resources communes
et
- main/resources/dev
- main/resources/test
- main/resources/recette
- main/resources/prod
qui contiennent les ressources spécifiques à des environnements.
On modifie le descripteur de projet en modifiantle pom.xml
<build>
[...]
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/${mode}</directory>
</resource>
</resources>
[...]
<build>
mercredi 3 octobre 2007
La génération d'un client Web-Service
La génération d'un client est en réalité la génération d'un certain nombre de fichier JAVA, ces fichiers seront par la suite compilé et permettrons de se connecter de manière simple au web service. Le processus le naturel pour générer un lient Web service est le suivant :
1- Télécharger le descripteur de déploiement
2- Générer le client à l'aide d'un assistant
3- Tester le service
Si le serveur est un serveur axis, http://monserveur.com/axis-webaapp/services donne accès à des liens vers les descripteur de déploiement. Sur le lien WSDL télécharger le descripteur de déploiement.
Se placer dans un projet java, on générera le client dans ce projet, par exemple, ws-test
Dans le menu Fichier --> Nouveau, choisir client de Web Service, on aboutit à l'écran suivant :

Dans le second écran on renseigne l'url ou se trouve le WSDL

Les options par défaut, génère seulement le client.
Pour se servir du service, on utilise Locator pour résoudre la localisation du service au niveau du réseau, des namespaces, puis on se sert du service comme s'il s'agissait d'une fonction tout à fait ordinaire.
1- Télécharger le descripteur de déploiement
2- Générer le client à l'aide d'un assistant
3- Tester le service
1- Télécharger le descripteur de déploiement
Si le serveur est un serveur axis, http://monserveur.com/axis-webaapp/services donne accès à des liens vers les descripteur de déploiement. Sur le lien WSDL télécharger le descripteur de déploiement.
And now... Some Services
- AdminService (wsdl)
- AdminService
- Version (wsdl)
- getVersion
- AidaService (wsdl)
- rechercherListeDossiers
- detailDossier
- QosService (wsdl)
- echo
2- Générer le client de Web service à l'aide d'un assistant
En utilisant Eclipse, la génération d'un client est très simple.Se placer dans un projet java, on générera le client dans ce projet, par exemple, ws-test
Dans le menu Fichier --> Nouveau, choisir client de Web Service, on aboutit à l'écran suivant :

Dans le second écran on renseigne l'url ou se trouve le WSDL

Les options par défaut, génère seulement le client.
3- Tester le service
Pour se servir du service, on utilise Locator pour résoudre la localisation du service au niveau du réseau, des namespaces, puis on se sert du service comme s'il s'agissait d'une fonction tout à fait ordinaire.
MyServiceLocator locator = new MyServiceLocator();
MyService service = locator.getMyService();
String result = service.fonction01("param1","param2");
Inscription à :
Articles (Atom)